|
I am an applied scientist at Amazon Prime Video. I work on computer vision and natural language processing. I obtained my Ph.D. degree from University at Buffalo, SUNY, where I was advised by Prof. Junsong Yuan. Before that, I worked at Nanyang Technological University. I received my Bachelor's degree from Xian Jiaotong University, where I was a member of the Special Class of the Gifted Young. Email / CV / Google Scholar / LinkedIn |

|
|
|
At Amazon, I work on image generation, 3D scene reconstruction, and large language models (LLMs) to support Virtual Product Placement for Prime Video contents. Our work on image compositing and structure-from-motion was published at CVPR'23 and CVPR'22, respectively. I also have solid knowledge of, and practical experience with, large language models (LLMs), such as aligning LLMs with human preferences via direct preference optimization (DPO) and retrieval augmented generation (RAG). Additionally, I proposed and co-led the development of a computer vision solution for real-time virtual product placement on Twitch. My Ph.D. research focused on vision-and-language (VL). Our work focused on vision-and-language pre-training, visual question answering, video captioning, visual grounding and machine translation. I also worked on neural rendering. We utilized neural radiance fields (NeRF) to learn kinematic formulas and create 3D avatars. |
|
|

|
Sheng Liu, Cong Phuoc Huynh, Cong Chen, Maxim Arap, Raffay Hamid CVPR, 2023 paper We designed a self-supervised pre-training method for image harmonization that outperforms existing methods while using less than 50% of the labeled training data they require. |

|
Sheng Liu, Xiaohan Nie, Raffay Hamid CVPR, 2022 paper / video / poster / data Leveraging depth priors enables DepthSfM to faithfully reconstruct 3D scene structures from movies, TV shows, and Internet photo collections. DepthSfM can reconstruct parts of Los Angeles from a 2-second clip of Bosch. Check out this video to see the results. |

|
Sheng Liu, Kevin Lin, Lijuan Wang, Junsong Yuan, Zicheng Liu AAAI, 2022 paper / video / data We introduced open-vocabulary visual instance search (OVIS) which aims to search for and localize visual instances using arbitrary textual queries, and developed a large-scale vision-and-language pre-trained model for OVIS. Check out this 1-minute demo video where we compare our model with Google and Bing. Our model uses only the visual information of images, while Google and Bing also leverage textual metadata. It's quite intriguing! 😜. |
|
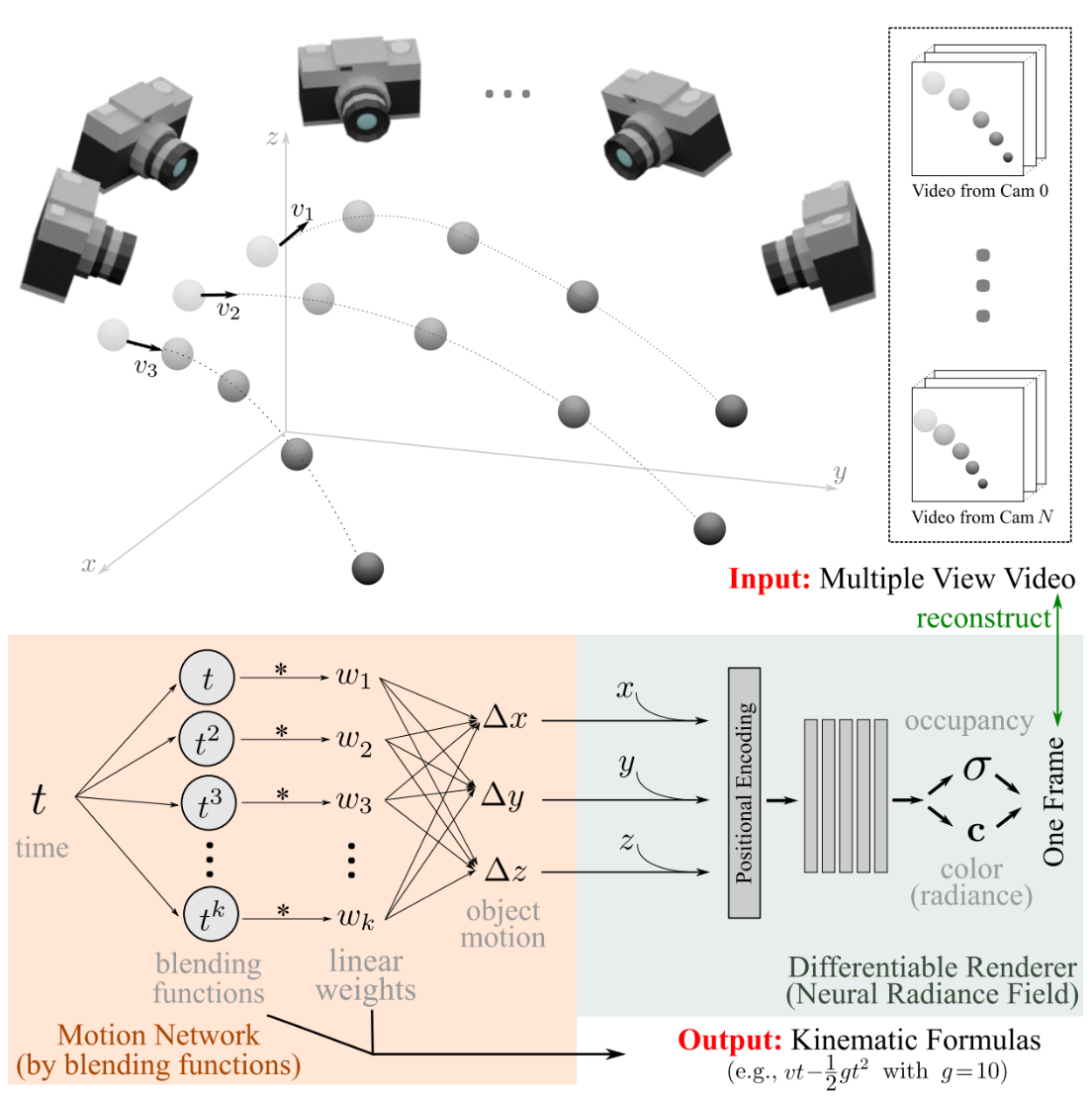
Liangchen Song* Sheng Liu*, Celong Liu, Zhong Li, Yuqi Ding, Yi Xu, Junsong Yuan ACM MM, 2022 * indicates equal contribution paper We proposed a novel framework capable of learning kinematic formulas, e.g., kinematic equations for objects in free fall, in an unsupervised manner by leveraging neural radiance fields (NeRF). |
|
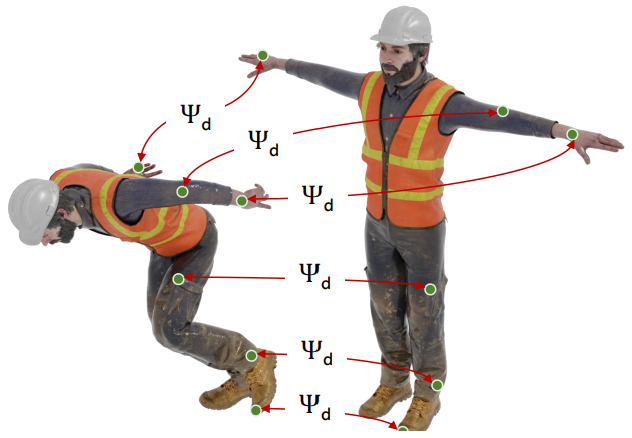
Sheng Liu*, Liangchen Song*, Yi Xu, Junsong Yuan VCIP, 2022 * indicates equal contribution paper We proposed a neural clothed human model, which learns neural radiance fields (NeRF) to represent 3D animatable avatars |
|
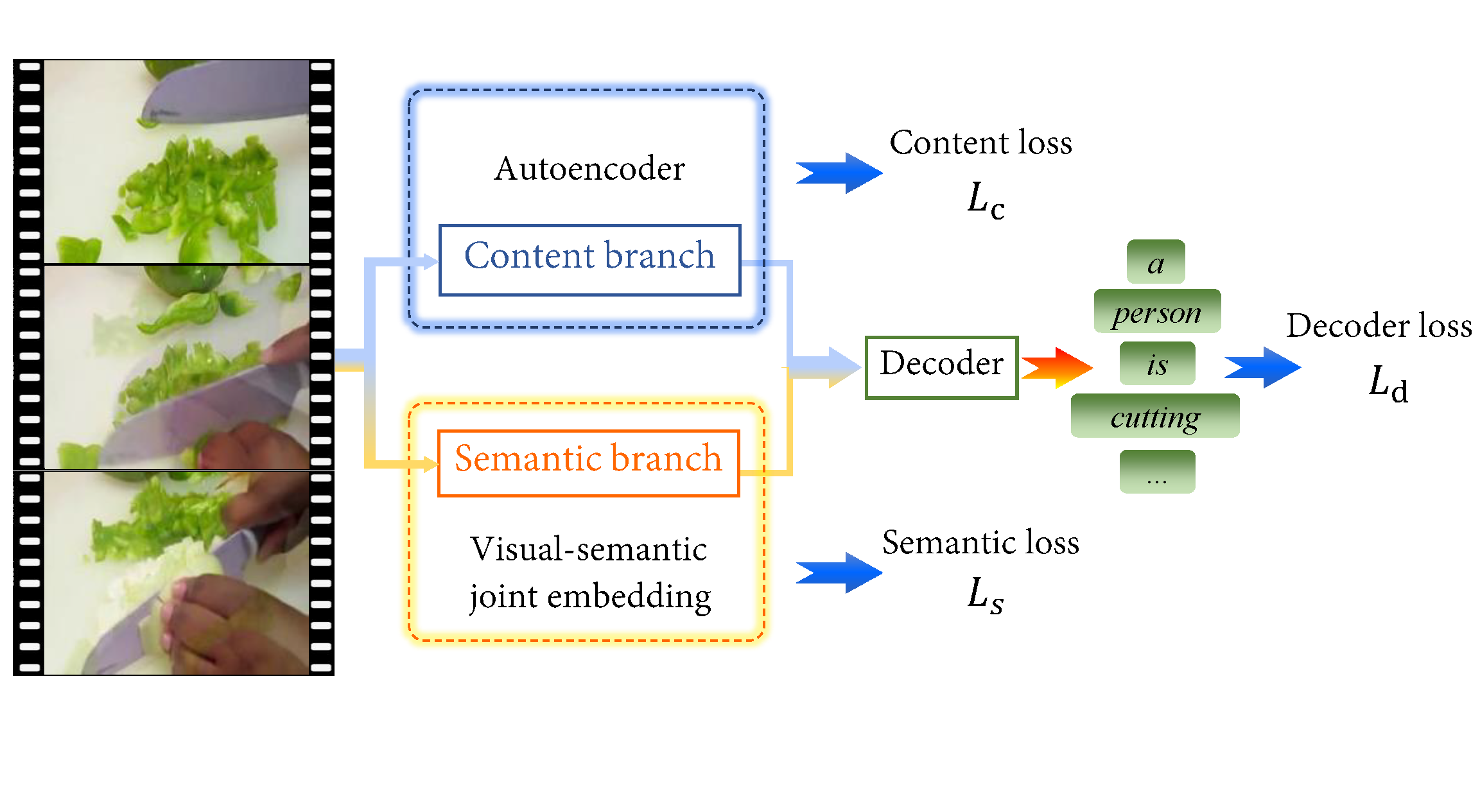
Sheng Liu, Zhou Ren, Junsong Yuan TPAMI, 2021 paper This is the journal version of our paper presented at ACM MM'18. We designed a two-branch visual encoder for video captioning: one branch encodes high-level semantic information, while the other encodes low-level content information of videos. |
|
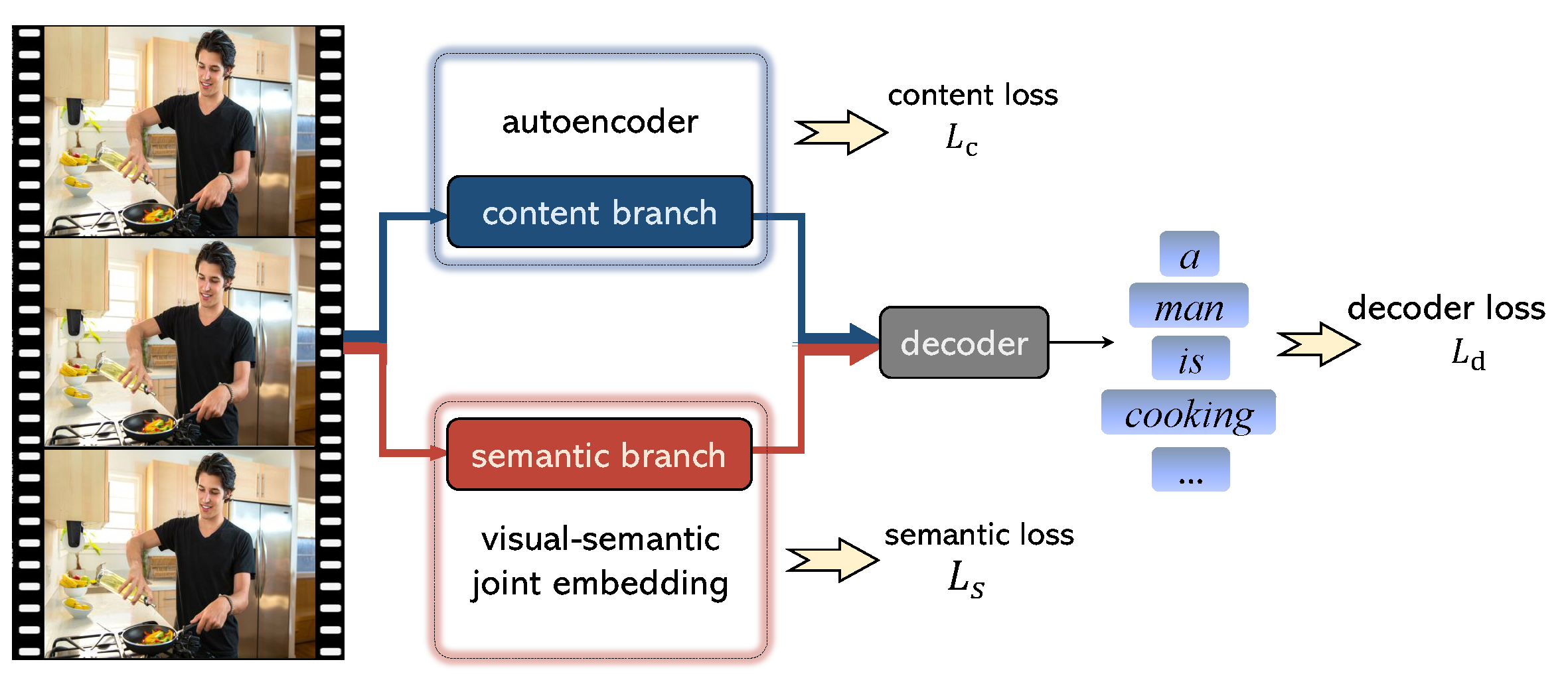
Sheng Liu, Zhou Ren, Junsong Yuan ACM MM, 2018 (Oral) paper We designed a two-branch visual encoder for video captioning: one branch encodes high-level semantic information, while the other encodes low-level content information of videos. |
|
|